
#AI reply classification: when AI SDRs misread replies
Copy page
TL;DR: AI reply classification sorts every prospect response into a bucket like positive, objection, question, out-of-office, or unsubscribe. It works well on clean single-signal replies and breaks on the ambiguous ones. A reply that pairs a timing objection with a real buying question gets filed on one signal while the other is lost, and the prospect gets the wrong follow-up or none at all.
Well-run AI SDRs handle 60 to 70 percent of replies on their own and route the mixed-intent middle to a human. The fix is not a smarter model. It is a confidence threshold honest enough to admit when the model is guessing.
#Table of contents
- What AI reply classification actually does
- The mixed-intent problem nobody designs for
- Five reply types that get misread
- Reply types, misread risk, and safe handling
- The cost of acting on the wrong read
- Why the confidence score lies to you
- Confidence thresholds done the right way
- The human in the loop catches the middle
- How to set this up without slowing down
- FAQs
- Conclusion
#What AI reply classification actually does
AI reply classification is the step where an AI SDR reads an inbound email reply and assigns it a label that decides what happens next. Most systems sort every reply into one of five buckets: positive, objection, question, unsubscribe, or out-of-office. The label is not cosmetic.
It triggers an action. Positive books a meeting or drafts a warm response. Objection fires a rebuttal sequence.
Unsubscribe suppresses the contact. Out-of-office pauses the cadence and reschedules.
That routing is the whole point. A rep handling 40 live conversations cannot read every reply within a minute of it landing. An AI agent can.
When the reply is clean, the agent is faster than a human and just as accurate. "Please remove me" is an unsubscribe. "Sounds great, what times work Thursday?" is positive.
"I'm out until July 8" is out-of-office. No ambiguity, no judgment call, no reason to wake a human.
The trouble starts when the reply carries more than one signal at once. Real buyers do not write in clean categories. They hedge.
They bury a question inside a brush-off. They say no to the timing and yes to the idea in the same two sentences. A classifier built to pick one label has to drop something, and what it drops is often the part that mattered.
Deep learning sentiment models top out around 83.3 percent accuracy on classification tasks, according to research comparing LSTM networks against older methods like SVM and Naive Bayes. That sounds high until you flip it. Roughly one in six replies gets the wrong read.
On a list where you worked hard to earn each response, one in six is a lot of misrouted intent.
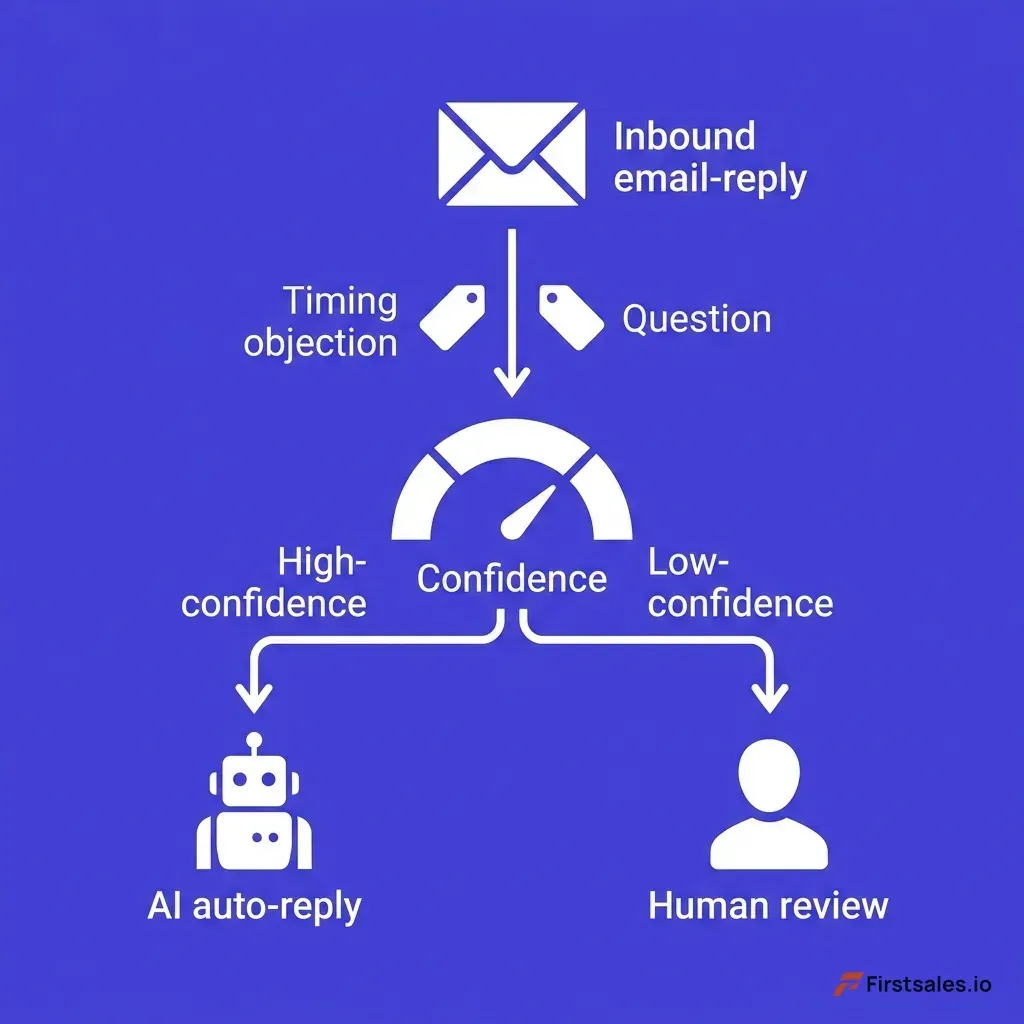 Decision-tree diagram showing one inbound reply tagged with two signals, a confidence gauge in the middle, and two routing paths splitting to an AI auto-reply robot and a human-review person
Decision-tree diagram showing one inbound reply tagged with two signals, a confidence gauge in the middle, and two routing paths splitting to an AI auto-reply robot and a human-review person
#The mixed-intent problem nobody designs for
Here is the failure mode in one line. The AI reads one signal, acts on it, and misses the other.
A prospect writes back: "We just renewed with our current vendor through Q3, but the routing piece you mentioned is interesting. How does it handle round-robin across time zones?"
A human reads that and sees a buyer. The timing is a real constraint, sure, but the question at the end is the tell. They are picturing your product inside their workflow.
That is a hand half-raised. The right move is to answer the question well, acknowledge the Q3 timing, and schedule a low-pressure conversation for when the renewal window opens.
A single-label classifier reads the first clause, tags the reply as an objection, fires the "handling a competitor" rebuttal, and never answers the question. Or it reads "renewed through Q3" as a soft no, marks the contact dead, and drops them from the pipeline entirely. Either way, the one sentence that signaled intent got thrown out with the bathwater.
Misclassifications cluster exactly here, on replies that hold mixed or ambiguous intent. The objection and the question are not in conflict. They are two true things the prospect said at the same time.
A model trained to output one bucket cannot represent "both," so it picks the louder one and discards the rest. Aggregate accuracy scores hide this, because they average the easy single-signal replies in with the hard ones. The number looks fine.
The lost deals do not show up in it.
This gets worse over time, not better. Concept drift, the slow shift of live reply patterns away from whatever the model was trained on, is one of the most underestimated problems in intent recognition. The phrasings buyers use this quarter are not the phrasings from the training set.
A classifier that was accurate at launch quietly degrades as language moves, and nobody notices until the pipeline thins out.
#Five reply types that get misread
Not every reply is equally dangerous. Some categories are reliably clean. Others are landmines.
These five are where classification errors do the most damage, because each one looks like a category it is not.
#Out-of-office that hides a real answer
Out-of-office replies are usually easy. Detect the auto-reply, pause the sequence, reschedule the next touch for after the stated return date. The mistake is sending a follow-up that lands the morning the prospect walks back to 600 unread emails.
Yours gets archived in the bulk delete.
The harder version is the out-of-office that contains routing information. "I'm out until Monday. For anything urgent, contact Priya (priya@company.com) who now owns our sales tooling decisions."
That is not just an OOO. It is a referral and a job-change signal buried in an autoresponder. A classifier that tags it OOO and moves on misses the most valuable line in the email: the name of the actual buyer.
#Referral that reads like a rejection
"This isn't really my area, you'd want to talk to someone on the RevOps side" is one of the highest-value replies you can get. The prospect just told you the door is open and pointed at who holds the key. Handled well, it becomes a warm internal introduction.
Handled by a blunt classifier, "isn't really my area" trips a negative-sentiment flag and the contact gets filed as not interested. The referral never gets actioned. You had a path in and the model closed it.
#Soft no with a buying signal inside
This is the renewal example from earlier, and it is the most common mixed-intent reply in B2B outbound. The structure is always the same: a constraint stated up front, an interest signal tucked behind it. "Budget's frozen until next fiscal, but send me a one-pager and I'll keep you in mind."
The frozen budget is real. So is the request for a one-pager. One of those is a reason to wait.
The other is a reason to stay close.
A classifier that weights the first clause kills the thread. The prospect asked for something and got silence, which reads as a company that does not follow through.
#Objection stacked on a question
"How is this different from what we already use, and honestly we don't have bandwidth to switch right now." Two signals again. The question deserves a real, specific answer.
The bandwidth objection deserves acknowledgment and a longer nurture horizon. Answer only the objection and you sound defensive. Answer only the question and you ignore a stated constraint, which makes the next email feel tone-deaf.
Objection handling is where fully autonomous AI SDRs most visibly break down. The replies that combine a competitive comparison or a pricing question with an emotional objection are precisely the ones a model should hand off, not autopilot.
#Sarcasm and dry humor
"Oh great, another outreach tool, exactly what my inbox was missing." A human reads the eye-roll instantly. A classifier might tag it positive on the words "great" and "missing," then send an enthusiastic booking link into a prospect who was mocking you.
Sarcasm is genuinely hard for text models. Without tone of voice or facial cues, even people misread sarcastic email, and the research on automated detection is blunt about how low accuracy stays. The safe assumption is that any reply scoring as borderline-positive with negative undertones should never auto-send.
It is a human read every time.
#Reply types, misread risk, and safe handling
The pattern across all five is that the dangerous replies are the ones where the obvious label is wrong. Here is how the common reply types map to their misread risk and the handling that keeps you out of trouble.
| Reply type | Common misread | Misread risk | Safe handling |
|---|---|---|---|
| Clean positive ("what times work?") | Rare | Low | AI auto-drafts, sends scheduling link |
| Clean unsubscribe ("remove me") | Rare | Low | AI suppresses contact immediately |
| Standard out-of-office | Sends follow-up on return day | Low to medium | AI pauses, reschedules after return date |
| OOO with referral or new contact | Tagged OOO, referral lost | High | Route to human, capture the new buyer |
| Referral ("not my area, talk to X") | Tagged not interested | High | Route to human, request warm intro |
| Soft no with buying signal | Tagged dead, dropped | High | Route to human, answer and nurture |
| Objection plus question | Answers one, ignores other | High | Route to human, address both signals |
| Sarcasm or dry humor | Tagged positive | High | Always human, never auto-send |
| Pricing or competitive question | Generic rebuttal fired | Medium to high | Route to human or sales engineer |
The rule that falls out of this table is simple. Single-signal replies are safe to automate. Multi-signal replies are not.
Your classifier does not need to be smarter at reading the hard ones. It needs to be honest about which ones are hard, and route those to a person. The reply handling playbook goes deeper on how to structure those routing rules across a full sequence.
#The cost of acting on the wrong read
A misread reply is not a neutral event. It costs you in three directions at once, and only one of them shows up in a dashboard.
The first cost is the lost deal. A soft-no-with-signal that gets dropped is a buyer who raised their hand and watched you walk away. You will never know it happened, because the contact just goes quiet in your CRM under a "not interested" tag that was wrong from the start.
These are the most expensive errors precisely because they are invisible. The reply that mattered got filed under a label that guarantees no human ever looks at it again.
The second cost is the relationship. When an AI fires a competitor-rebuttal at someone who asked a genuine question, or sends a chipper booking link to someone being sarcastic, the prospect learns something about your company. They learn a bot is running your outbound and nobody is checking its work.
That impression sticks. It does not just cost you this deal. It poisons the next three times you reach out.
The third cost is deliverability and compliance. A misclassified reply that triggers an off-brand or non-compliant response is the kind of failure that draws spam complaints and, in regulated industries, worse. Send the wrong automated message to someone who explicitly asked to be left alone and you have a complaint, a reputation hit, and potentially a legal one.
The same risk surfaces in the broader set of AI SDR mistakes that quietly degrade a sending program from the inside.
Put those together and the math on full autonomy stops working. The replies an AI handles perfectly save you time. The replies it misreads cost you deals, relationships, and domain health.
A system that automates everything optimizes for the wrong half of that trade.
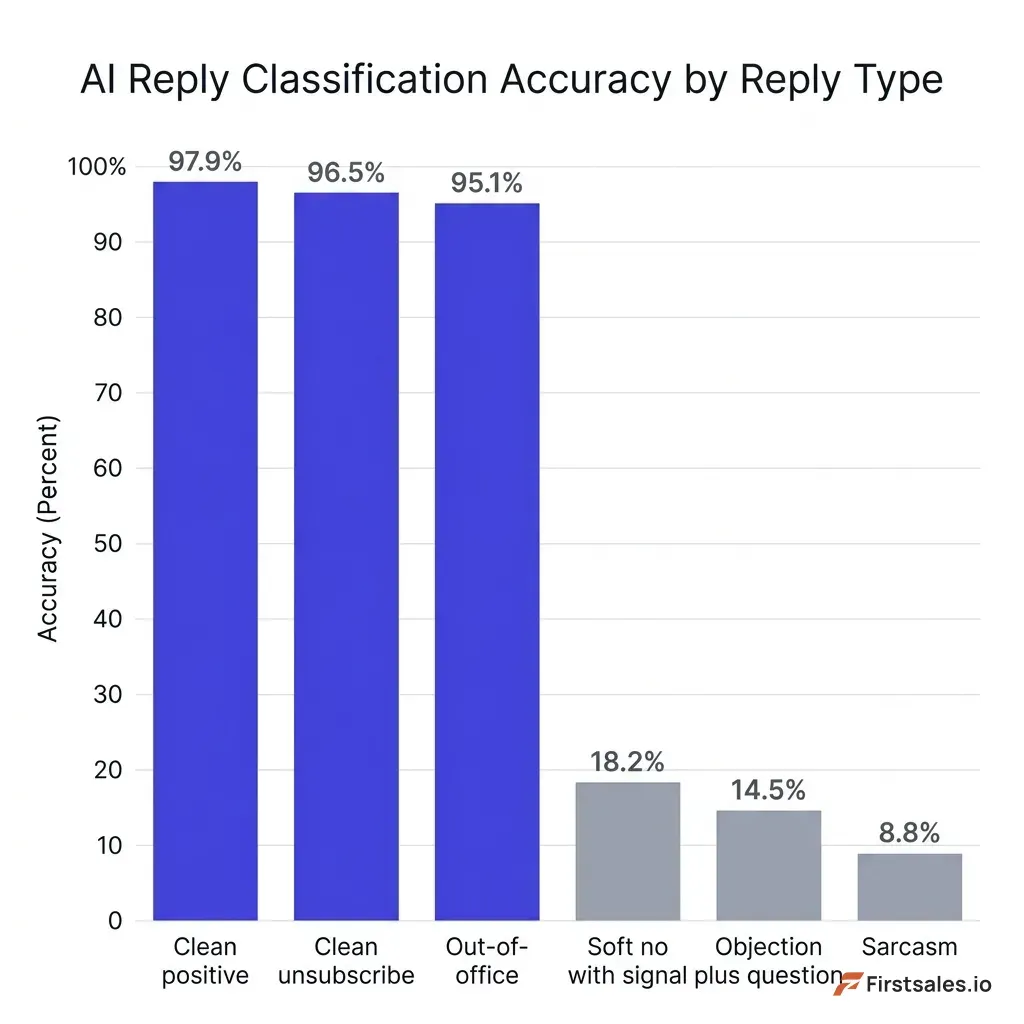 Bar chart comparing classification accuracy across reply types, showing high accuracy on clean single-signal replies and a sharp drop on mixed-intent replies like soft-no-with-signal, objection-plus-question, and sarcasm
Bar chart comparing classification accuracy across reply types, showing high accuracy on clean single-signal replies and a sharp drop on mixed-intent replies like soft-no-with-signal, objection-plus-question, and sarcasm
#Why the confidence score lies to you
The obvious fix is a confidence threshold. Let the AI act when it is sure, and escalate when it is not. The instinct is right.
The trap is trusting the confidence number itself.
Models tuned with reinforcement learning from human feedback are systematically overconfident. The training rewards assertive answers over honest uncertainty, so the model learns to sound sure whether or not it should be. The gap is large and well documented.
On the SimpleQA benchmark, GPT-4o reported 93 percent confidence on claims that turned out to be true only 35 percent of the time, according to the research in Mind the Confidence Gap. A stated 90 percent often maps to actual accuracy closer to 65 percent. Large tuned models cluster their confidence scores between 80 and 100 percent and rarely admit doubt, with expected calibration error reaching 0.30 or higher on knowledge-heavy tasks.
Read that again in the context of reply routing. If you set your escalation rule at "act when confidence is above 85 percent," and the model is overconfident by 20-plus points, you have built a gate that lets almost everything through while believing it is selective. The mixed-intent replies, the ones you most need to catch, are exactly where the model is both wrong and loudly certain.
Your model is most wrong when it sounds most sure.
This is why a raw confidence threshold, applied naively, gives you a false sense of safety. The number is real. What it measures is not what you think.
You are thresholding against a value the model inflated during training, and the inflation is worst on the hard cases.
#Confidence thresholds done the right way
The better question is not "how sure is the agent?" It is "how bad is it if the agent is wrong?" Those are different axes, and the second one matters more.
A widely-used production pattern stops relying on confidence alone and classifies every possible action by its reversibility and blast radius, then assigns an oversight mode to each tier. Sending a scheduling link is reversible and low blast radius. Suppressing a contact or firing a rebuttal at a frozen account is not.
High confidence does not earn the agent the right to take an irreversible action unsupervised. The action's cost sets the gate, and confidence only adjusts where inside that gate the line sits.
For reply handling, that translates into a layered rule:
The action determines the floor. Auto-replies that book or answer can run at a moderate confidence bar because the worst case is a slightly-off message a prospect can correct. Actions that close a door, suppress, mark dead, fire an objection sequence, get a stricter bar and, for high-stakes intents, no autopilot at all.
The signal count overrides confidence. If the classifier detects more than one intent in a single reply, route to a human regardless of the confidence on either label. A multi-signal reply is a definitional escalation, because the model has to discard something to produce a single answer, and the thing it discards is unobservable from the confidence score.
Low confidence does something specific. It does not silently pick the most likely label. It abstains, asks a clarifying internal flag, or falls back to a safe default of human review.
Deciding what low confidence does is the actual design work, and the default has to be safe rather than convenient.
This is the same principle that separates an autonomous cold email agent that quietly burns a list from one that compounds pipeline. The autonomy is not the feature. The judgment about when to withhold autonomy is.
#The human in the loop catches the middle
Here is the finding that should reshape how you think about AI reply handling. Well-configured AI SDRs handle 60 to 70 percent of follow-up responses on their own. Those are the pattern-based replies: timing delays, information requests, simple routing questions, clean OOOs.
The remaining 30 to 40 percent, the competitive comparisons, the pricing negotiations, the technical questions, the mixed-intent replies, escalate to a human.
That split is not a weakness in the system. It is the system working as designed. The value of an AI SDR is not that it replies to everything.
It is that it clears the easy 65 percent off your reps' plates so they spend their attention on the 35 percent where a human read changes the outcome. Automate the clear replies. Surface the ambiguous ones to a person with the context already assembled.
This is the model FirstSales is built around. The AI drafts, classifies, and handles the clean replies at speed. When a reply carries mixed intent, scores as borderline, or would trigger an irreversible action, it does not send.
It routes the reply to a rep with both detected signals flagged and a suggested response already drafted, so the human spends 30 seconds confirming a judgment rather than five minutes reconstructing context. The supervision layer is not overhead bolted onto automation. It is the part that makes the automation safe to run at all.
The difference between a tool that does this and one that does not is the difference described in AI SDR versus AI-assisted SDR. A fully autonomous agent treats every reply as something to answer. An AI-assisted system treats the ambiguous reply as something to escalate.
The second one keeps the deals the first one quietly loses.
What the human actually adds at the escalation point is small and specific. They confirm the dominant intent when two signals compete. They catch the sarcasm the model read as positive.
They notice the new buyer's name hiding in the out-of-office. They decide whether "send me a one-pager" is a polite brush-off or a real request. None of that takes long.
All of it is the part a single-label model cannot do, and all of it is where the money is.
The broader case for keeping a person on the human-in-the-loop cold email workflow rests on exactly these moments.
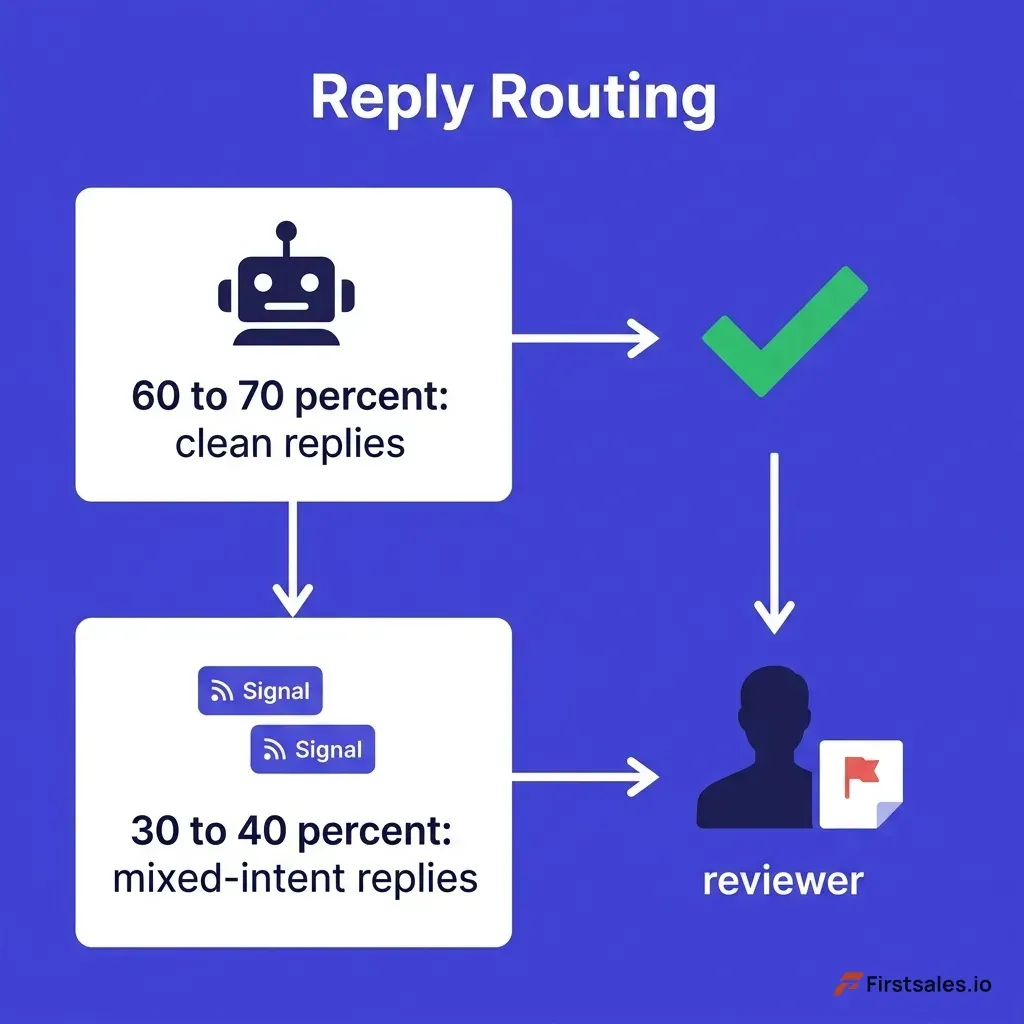 Vertical infographic showing the 60-70 percent of clean replies handled by AI on one path and the 30-40 percent of mixed-intent replies routed to a human reviewer with both signals flagged, on a deep indigo and white flat design
Vertical infographic showing the 60-70 percent of clean replies handled by AI on one path and the 30-40 percent of mixed-intent replies routed to a human reviewer with both signals flagged, on a deep indigo and white flat design
#How to set this up without slowing down
You do not need to rebuild your stack to fix misclassification. You need to change three settings and one habit.
Set the agent to draft, not autopilot, on anything stakeful. In most AI reply tools, including the AI Reply Agent settings in platforms like Instantly, you can set the agent to draft replies for human approval rather than send them directly. Turn that on for objections, referrals, and anything the classifier scores below your action-cost threshold. Leave autopilot on only for clean positives, clean unsubscribes, and standard OOOs.
Make multi-signal detection a hard escalation. Configure the routing so that any reply where the model detects two or more intents goes to a human no matter how confident it is on either one. This single rule catches most of the expensive errors, because the expensive errors are almost all mixed-intent.
Treat high-cost intents as no-autopilot zones. Suppression, marking a contact dead, and firing a competitive rebuttal are actions you cannot take back. Gate them behind human review permanently, regardless of confidence. The cost of a wrong unsubscribe or a wrong "not interested" tag is too high to automate.
Review the corrections weekly. Every time a rep changes a drafted reply before sending, that is a labeled training signal pointing at a gap. Read those edits once a week. The patterns in them tell you where your classifier drifts, which phrasings it keeps misreading, and where to tighten the rules.
This is the loop that fights concept drift, and it costs 20 minutes.
The teams getting real pipeline out of AI SDRs are not the ones with the most autonomous setup. They are the ones who automated the clear 65 percent ruthlessly and put a human on the ambiguous 35 percent every single time. Speed on the easy replies, judgment on the hard ones.
That is the whole design.
#FAQs
#What is AI reply classification in cold email?
AI reply classification is the process where an AI SDR reads a prospect's email reply and assigns it a label such as positive, objection, question, out-of-office, or unsubscribe. That label decides the next action, whether to book a meeting, send a rebuttal, pause the sequence, or suppress the contact. The classification is accurate on clean single-signal replies and unreliable on replies that carry more than one intent at once.
#Why do AI SDRs misread replies?
AI SDRs misread replies because most classifiers are built to output one label, and real replies often contain two or more signals. A reply that pairs a timing objection with a buying question forces the model to pick one and discard the other. The discarded signal is frequently the one that mattered, which is how a half-raised hand gets filed as a hard no.
#What is the mixed-intent problem?
The mixed-intent problem is when a single reply expresses two true things at once, like a constraint and an interest signal, and a single-label classifier can only capture one. For example, "budget's frozen but send me a one-pager" is both a soft no and a real request. The model reads one clause, acts on it, and misses the other, sending the wrong follow-up or none at all.
#How accurate is AI at classifying sales replies?
Deep learning sentiment models reach around 83.3 percent accuracy on classification tasks, based on research comparing LSTM networks to older methods. That means roughly one in six replies gets misread, and the errors concentrate on mixed-intent and ambiguous replies rather than spreading evenly. Aggregate accuracy scores hide this because they average the easy replies in with the hard ones.
#Should I trust the AI's confidence score for routing?
Not on its own. Models tuned with reinforcement learning from human feedback are systematically overconfident, with a stated 90 percent confidence often mapping to actual accuracy closer to 65 percent. On the SimpleQA benchmark, GPT-4o reported 93 percent confidence on claims that were correct only 35 percent of the time.
The model is often most confident exactly when it is wrong, especially on the hard replies you most need to catch.
#What reply types are most dangerous to automate?
The highest-risk types are referrals that read like rejections, soft nos with a buying signal inside, objections stacked on a question, out-of-office replies that hide a new contact, and sarcasm. Each one looks like a category it is not, so a blunt classifier files it under the wrong label. These should route to a human rather than auto-send.
#How much of reply handling should be automated?
Well-configured AI SDRs handle 60 to 70 percent of replies autonomously, which are the pattern-based ones like timing delays, information requests, and clean out-of-office messages. The remaining 30 to 40 percent, including competitive comparisons, pricing questions, and mixed-intent replies, should escalate to a human. Automating beyond that range starts costing you deals the model misreads.
#How do I stop my AI from sending follow-ups to out-of-office replies?
Configure the agent to detect out-of-office signals, pause the sequence automatically, and reschedule the next touchpoint for after the stated return date. The common mistake is sending a follow-up that lands the day the prospect returns to a full inbox, where it gets archived in a bulk delete. Avoid scheduling any touch on or immediately after a known return date.
#What is human-in-the-loop reply handling?
Human-in-the-loop reply handling is a design where the AI drafts and classifies replies but a person approves anything ambiguous or high-stakes before it sends. The AI clears the clear replies at speed and routes mixed-intent or borderline replies to a rep with both signals flagged and a draft prepared. The human spends seconds confirming a judgment instead of minutes rebuilding context.
#Does using AI for reply handling hurt my deliverability?
It can, if the AI auto-sends misclassified replies. A wrong automated message to someone who asked to be removed generates spam complaints and reputation damage, and in regulated industries it can create compliance exposure. Gating irreversible actions like suppression and rebuttals behind human review protects both your domains and your prospect relationships.
#How do I fix a classifier that keeps misreading replies?
Review the corrections weekly. Every time a rep edits a drafted reply before sending, that edit points at a gap in the classifier, so read those cases once a week to spot recurring misreads. This fights concept drift, the slow shift of live reply patterns away from the training data, which degrades classification accuracy over time if nobody monitors it.
#What is the difference between an AI SDR and an AI-assisted SDR for replies?
A fully autonomous AI SDR treats every reply as something to answer on its own. An AI-assisted SDR treats ambiguous replies as something to escalate to a human while automating the clear ones. The AI-assisted model keeps the deals that full autonomy quietly loses, because the human catches the mixed-intent replies a single-label classifier cannot represent.
#Conclusion
AI reply classification is good at what it is good at. Clean replies get the right label and the right action faster than any human could manage across a full pipeline. The problem was never the easy 65 percent.
It is the ambiguous middle, where a single reply holds two signals and a single-label model has to throw one away.
The misreads cost more than they appear to, because the worst of them are invisible. A soft no with a buying signal, dropped under a "not interested" tag, never shows up in a dashboard as a lost deal. It just goes quiet.
The relationship damage and the deliverability risk pile on top of that, and the math on full autonomy stops working.
The fix is not a smarter classifier chasing a few more points of accuracy. It is a system honest about its own uncertainty. Gate irreversible actions behind human review.
Escalate any reply with more than one intent, no matter how confident the model sounds, because the confidence score is inflated worst on the cases you most need to catch. Automate the clear replies ruthlessly and put a person on the ambiguous ones every time.
FirstSales is built for exactly that split: signal-based prospecting, AI-drafted replies that move fast on the clean ones, and a human-in-the-loop layer that surfaces the mixed-intent reply with both signals flagged before anything sends. Start your first campaign for $1 at https://app.firstsales.io and let the AI handle the easy replies while your reps keep the deals the bots drop.


